题目描述:给定一个二叉树, 找到该树中两个指定节点的最近公共祖先。
百度百科中最近公共祖先的定义为:“对于有根树 T 的两个结点 p、q,最近公共祖先表示为一个结点 x,满足 x 是 p、q 的祖先且 x 的深度尽可能大(一个节点也可以是它自己的祖先)。”
例如,给定如下二叉树: root = [3,5,1,6,2,0,8,null,null,7,4]
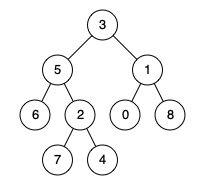
示例 1:
输入: root = [3,5,1,6,2,0,8,null,null,7,4], p = 5, q = 1
输出: 3
解释: 节点 5 和节点 1 的最近公共祖先是节点 3。示例 2:
输入: root = [3,5,1,6,2,0,8,null,null,7,4], p = 5, q = 4
输出: 5
解释: 节点 5 和节点 4 的最近公共祖先是节点 5。因为根据定义最近公共祖先节点可以为节点本身。说明:
- 所有节点的值都是唯一的。
- p、q 为不同节点且均存在于给定的二叉树中。
1 | /** |
方法一:递归
若 root 是 p, q 的 最近公共祖先 ,则只可能为以下情况之一:
- p 和 q 在 root 的子树中,且分列 root 的 异侧(即分别在左、右子树中);
- p = root,且 q 在 root 的左或右子树中;
- q = root,且 p 在 root 的左或右子树中;
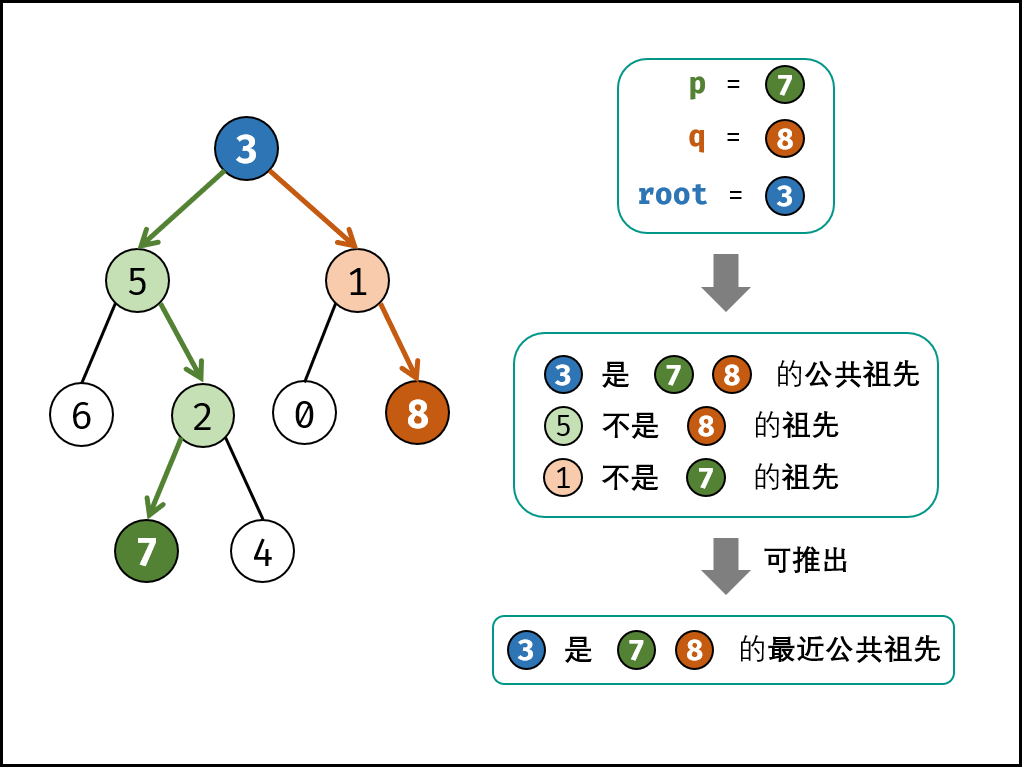
递归解析:
- 终止条件:
- 当越过叶节点,则直接返回 null ;
- 当 root 等于 p, q,则直接返回 root;
- 递推工作:
- 开启递归左子节点,返回值记为 left ;
- 开启递归右子节点,返回值记为 right ;
- 返回值: 根据 left 和 right ,可展开为四种情况;
- 当 left 和 right 同时为空 :说明 root 的左 / 右子树中都不包含 p,q ,返回 null ;
- 当 left 和 right 同时不为空 :说明 p, q 分列在 root 的 异侧 (分别在 左 / 右子树),因此 root 为最近公共祖先,返回 root ;
- 当 left 为空 ,right 不为空 :p,q 都不在 root 的左子树中,直接返回 right 。具体可分为两种情况:
- p,q 其中一个在 root 的 右子树 中,此时 right 指向 p(假设为 p );
p,q 两节点都在 root 的 右子树 中,此时的 right 指向 最近公共祖先节点 ;
- p,q 其中一个在 root 的 右子树 中,此时 right 指向 p(假设为 p );
- 当 left 不为空 ,right 为空 :与情况 3. 同理;
- 动图
1 | class Solution { |
复杂度分析:
- 时间复杂度 O(N):其中 N 为二叉树节点数;最差情况下,需要递归遍历树的所有节点
- 空间复杂度 O(H):最差情况下,递归深度达到 H ,系统使用 O(H) 大小的额外空间
执行结果:通过
执行用时:7 ms, 在所有 Java 提交中击败了100.00%的用户
内存消耗:41.8 MB, 在所有 Java 提交中击败了58.82%的用户
方法二:迭代
要想找到两个节点的最近公共祖先节点,我们可以从两个节点往上找,每个节点都往上走,一直走到根节点,那么根节点到这两个节点的连线肯定有相交的地方,如果是从上往下走,那么最后一次相交的节点就是他们的最近公共祖先节点。我们就以找6和7的最近公共节点来画个图看一下
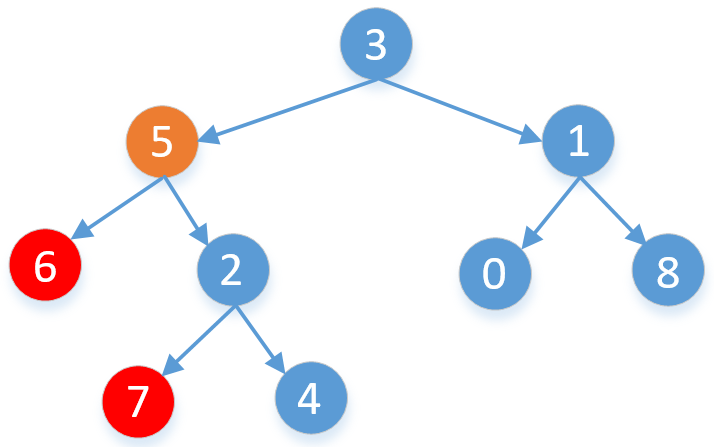
我们看到6和7公共祖先有5和3,但最近的是5。我们只要往上找,找到他们第一个相同的公共祖先节点即可,但怎么找到每个节点的父节点呢,我们只需要把每个节点都遍历一遍,然后顺便记录他们的父节点存储在Map中。我们先找到其中的一条路径,比如6→5→3,然后在另一个节点往上找,由于7不在那条路径上,我们找7的父节点是2,2也不在那条路径上,我们接着往上找,2的父节点是5,5在那条路径上,所以5就是他们的最近公共子节点。
其实这里我们可以优化一下,我们没必要遍历所有的结点,我们一层一层的遍历(也就是BFS),只需要这两个节点都遍历到就可以了,比如上面2和8的公共结点,我们只需要遍历到第3层,把2和8都遍历到就行了,没必要再遍历第4层了。
1 | public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) { |
复杂度分析
时间复杂度:O(N),其中 N 是二叉树的节点数。二叉树的所有节点有且只会被访问一次,从 p 和 q 节点往上跳经过的祖先节点个数不会超过 N,因此总的时间复杂度为 O(N)。
空间复杂度:O(N) ,其中 N 是二叉树的节点数。递归调用的栈深度取决于二叉树的高度,二叉树最坏情况下为一条链,此时高度为 N,因此空间复杂度为 O(N),哈希表存储每个节点的父节点也需要 O(N) 的空间复杂度,因此最后总的空间复杂度为 O(N)。
执行结果:通过
执行用时:12 ms, 在所有 Java 提交中击败了12.52%的用户
内存消耗:38.2 MB, 在所有 Java 提交中击败了100.00%的用户